

2D Prefix Array And 2D Segment Tree Overview
G
👋 Front-End Developer with a flair for competitive programming & robotics. Expert in 3D CAD design, YouTube educator. Innovating from Oaxaca, México.
Search for a command to run...
👋 Front-End Developer with a flair for competitive programming & robotics. Expert in 3D CAD design, YouTube educator. Innovating from Oaxaca, México.
No comments yet. Be the first to comment.
Hello everyone 👋, welcome back to another article, today are going to dive into a very cool graph algorithm called "Tarjan", we are going to see what it is, how it works, what it's used for, and we are going to upsolve two very cool competitive prog...
Introduction Hello everyone! 😄 Welcome back to my blog! Today, we're diving into the fascinating world of greedy algorithms in competitive programming. If you've ever wondered how to spot a problem screaming for a greedy solution or how to tackle th...
Introduction Hey there, fellow coders! Today, we're going to navigate through the exciting world of dynamic programming, tackling a captivating competitive programming problem along the way. We'll be stepping into the shoes of game strategists, playi...
Introduction Hello everyone, in this post we will look in detail at the solution to two similar, very classic DP problems: 'Roads' and 'Organizing Tiles', as well as their implementation in C++, altho the solution can be implemented in the language o...
Hello everyone, in this post we'll be mastering the 2D prefix sum array and 2D segment Tree while we solve a very interesting competitive programming problem to better understand these structures and their capabilities.
You are given an n x n grid representing the map of a forest. Each square is either empty or contains a tree. The upper-left square has coordinates (1,1)(1,1), and the lower-right square has coordinates (n,n).
Your task is to process K queries of the form: how many trees are inside a given rectangle zone in the forest?
In the first line, you are given two integers, N and Q, where N represents the size of the forest, and Q, the number of Queries you need to answer. Then you will receive N x N characters representing the forest. '.' represents an empty space and '*' a tree.
Lastly, you will get Q lines in the form of x1, y1, x2, and y2 which correspond to the corners of a rectangle zone.
For each query output the amount of trees inside the rectangular zone.
1 ≤ n ≤ 10000
1 ≤ q ≤ 200,000
1 ≤ y1 ≤ y2 ≤ n
1 ≤ x1 ≤ x2 ≤n
When first tasked with this problem, the clearest solution was to iterate through every square in the rectangular zone while adding the values into a counter variable for every query. Such a solution can be implemented like this:
#include<iostream>
using namespace std;
typedef long long ll;
char map[1005][1005];
ll query(int x1, int y1, int x2, int y2){
ll res = 0;
for(int i = x1; i<=x2; i++){
for(int j = y1; j<=y2; j++){
if(map[i][j] == '*')res++;
}
}
return res;
}
int main(){
int n, k;
cin >> n >> k;
for(int i=0; i<n; i++)for(int j=0; j<n; j++)cin >> map[i][j];
while (k--){
int x1, y1, x2, y2; cin >> x1 >> y1 >> x2 >> y2;
x1--; y1--; x2--; y2--;
cout << query(x1, y1, x2, y2) << "\n";
}
return 0;
}
Reading the input: The code reads the values of n and k, which takes constant time. Then it reads the n x n characters of the map, resulting in a time complexity of O(n^2).
Query Calculation: For each query, the code iterates over the rectangular region defined by x1, y1, x2, and y2. Since in a worst-case scenario you are prompted with x1 = 1, y1 = 1, x2 = n, y2 = n. This means that the entire map will be traversed resulting in a time complexity of O(n^2).
since we have to answer 200,000 queries and each of them cost 10,000^2 that means that in a worst-case scenario, we have to compute 20,000,000,000,000 operations which exceeds the 400,000,000 limit resulting in a TLE (Time Limit Exceded) verdict.
Let's improve our solution by implementing a technic called Prefix sum Array, the way it works is that we create a helper array that stores the sum of the elements of the original array up to a certain index, basically, the value at index i is going to represent the sum of all elements from index 0 to index i in the original array. Let's see an example:

Why is this useful? well, notice how the last index contains the sum of all elements from [0, 8] of the original array. Let's say you want to find the sum of all the elements between [2, 4] positions in the original array. With a prefix sum array, you can compute the sum in constant time (very fast) by subtracting two elements from the prefix sum array:
Sum = PrefixSum[5] - PrefixSum[2] = 12 - 5 = 7.
Notice how the prefix sum array has an extra zero at the beginning, this is simply to make the implementation of the queries more straightforward and avoid an index out-of-range error.

Knowing this we can implement a prefix sum array for each row in our forest map and of course, we must change the characters to their corresponding values, 1 or 0. Here is my implementation:
#include<iostream>
using namespace std;
typedef long long ll;
char map[1005][1005];
ll mapRowPrefix[1005][1005];
ll query(int x1, int y1, int x2, int y2){
ll res = 0;
for(int i = x1; i<=x2; i++) res += mapRowPrefix[i][y2+1] - mapRowPrefix[i][y1];
return res;
}
int main(){
int n, q;
cin >> n >> q;
for(int i=0; i<n; i++){
for(int j=0; j<n; j++){
cin >> map[i][j];
mapRowPrefix[i][j+1] = mapRowPrefix[i][j] + (map[i][j] == '*'?1:0);
}
}
while (q--){
int x1, y1, x2, y2; cin >> x1 >> y1 >> x2 >> y2;
x1--; y1--; x2--; y2--;
cout << query(x1, y1, x2, y2) << "\n";
}
return 0;
}
We still have to iterate through all the rows, which in a worst-case scenario it's N for each query. This means that the overall code has a time complexity of O(N^2 + (N * Q)). If we do the math this results in approximately 2,100,000,000 operations. We can clearly see an improvement compared to our previous solution, unfortunately, this still exceeds our 400,000,000 limit. 😥
In order to solve this problem we need to make it even more optimal by using a 2D prefix sum Matrix and by doing this removing the need to iterate through the rows.
Since you're familiar with the concept of a prefix sum array, understanding a 2D prefix sum matrix should be straightforward. It's basically the extension of the prefix sum array concept into two dimensions.
Given a 2D grid (or matrix), the 2D prefix sum matrix is another 2D grid of the same size where each cell (i,j) represents the sum of all the values in the rectangle from the top-left cell (0,0) to the current cell (i,j) in the original matrix. This can be clearly understood with the help of an example:
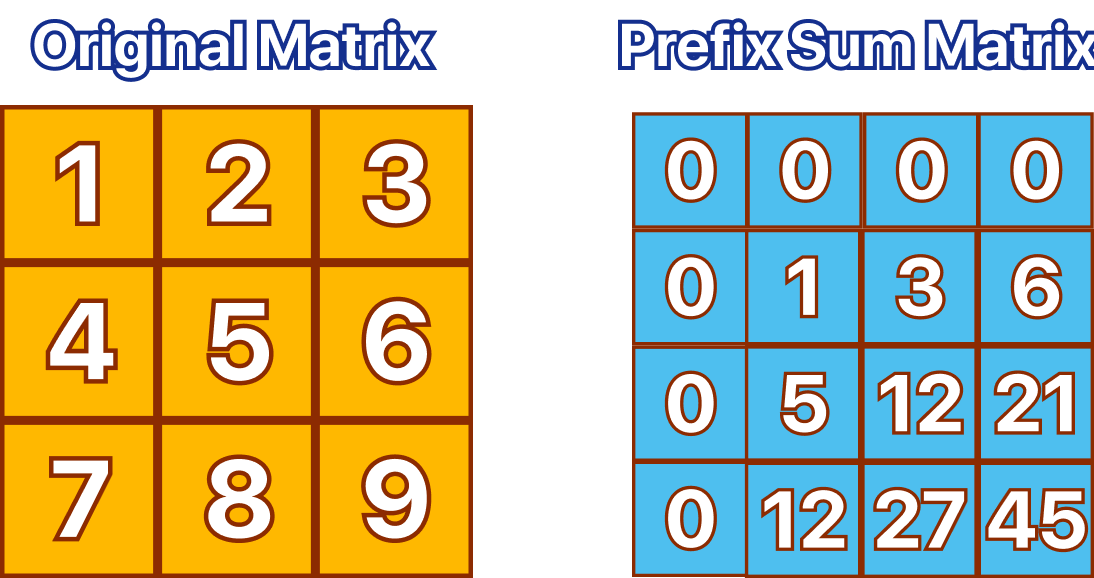
Calculating the Prefix Sum Matrix values is very simple, notice how once again we added an extra zero at the beginning of each row and each column, this once again just makes the implementation easier since we don't have to worry about creating a special case for those values and we don't worry about index out of range errors.
Excluding those extra zeros, filling the rest of the prefix sum Matrix values just evaluates to summing the value on the square above, the value on the square on the left, and the original value. Then subtract the value on the adjacent top left corner like this:
prefix2D[i][j] = prefix2D[i-1][j] + prefix2D[i][j-1] - prefix2D[i-1][j-1] + map[i][j];
By using this 2D prefix SumMatrix we can answer each query in constant time O(1) with the following operation:
sum = prefix2D[x2 + 1][y2 + 1] - prefix2D[x1][y2 + 1] - prefix2D[x2 + 1][y1] + prefix2D[x1][y1]
Knowing this allows us to solve the problem in a very efficient way, here is my code implementation:
#include<iostream>
using namespace std;
typedef long long ll;
char map[1005][1005];
ll prefix2D[1005][1005];
int main(){
int n, k;
cin >> n >> k;
for(int i=1; i<=n; i++){
for(int j=1; j<=n; j++){
cin >> map[i][j];
prefix2D[i][j] = prefix2D[i-1][j] + prefix2D[i][j-1] - prefix2D[i-1][j-1] + (map[i][j] == '*'?1:0);
}
}
while (k--){
int x1, y1, x2, y2; cin >> x1 >> y1 >> x2 >> y2;
x1--; y1--; x2--; y2--;
cout << (prefix2D[x2 + 1][y2 + 1] - prefix2D[x1][y2 + 1] - prefix2D[x2 + 1][y1] + prefix2D[x1][y1]) << "\n";
}
return 0;
}
Constructing the map and prefix2D arrays: O(n^2). You're performing n operations (for each row), each of which involves n operations (for each column). This remains the same as the previous solutions.
Querying k ranges: O(k). You're performing k operations, each of which is a constant time operation thanks to the 2D prefix Matrix.
Therefore, the overall time complexity of the program is O(n^2 + k) which evaluates to approximately 100,200,000 operations, this is well within our 400,000,000 limit that is set by most online judges.
This code is efficient and will get AC (Accepted) verdict. 🥳😁
Let's make this problem more interesting by adding updates. In this version of the previous problem, you are going to process K actions that can either type 1 or 2.
Change the state of a square, this means that if the square has a tree you can cut it down making the square empty, or if the square is empty you can plant a tree.
Query, the same thing as before, you are given the coordinates of a rectangle zone and you must output how many trees are completely inside the zone.
In the first line, you are given the integers N and K, the size of the forest and K actions, then there are N * N characters representing the map. Finally, you are given K actions, the format of each action can either be: "1 x y" or "2 x1 y1 x2 y2".
For each action of type 1 you don't need to print anything, just output the answer for each query of type 2.
1 ≤ n ≤ 10,000
1 ≤ q ≤ 200,000
1 ≤ y,x ≤ n
1 ≤ y1 ≤ y2 ≤ n
1 ≤ x1 ≤ x2 ≤ n
Up until this point, you can likely implement the most simple solution that involves iterating all of the squares inside the rectangle zone query and summing the values just like we did in the previous solution, however, now we must now add the Update functionality, which for this solution is super easy since we just have to add:
void update(int x, int y){
map[x][y] = map[x][y] == '*'?'.':'*';
}
If you are not familiar with this syntaxis, don't worry, it's called a ternary operator and does exactly the same as the code cell below but in a single line 😎.
void update(int x, int y){
if (map[x][y] == '*') {
map[x][y] = '.';
} else {
map[x][y] = '*';
}
}
This update solution is super efficient since it works on O(1) constant time. However, as we saw before, the query function has a time complexity of O(N^2).
As the competitive programmers that we are, we must assume the worst case that it's when absolutely all actions are queries and the queries ask for the sum of the entire map.
This means that the time complexity of this solution is going to be O(n^2 + (K * N^2)) which of course, is going to give a TLE verdict even though the updates happen in O(1) constant time.
Previously we saw how this was the best solution since each query was computed in O(1) constant time. Let's see how we can adjust this structure to support updates.
void update(int x, int y, int n){
map[x][y] = map[x][y] == '*' ? '.':'*';
for(int i=x; i<=n; i++){
for(int j=y; j<=n; j++){
prefix2D[i][j] = prefix2D[i-1][j] + prefix2D[i][j-1] - prefix2D[i-1][j-1] + (map[i][j] == '*'?1:0);
}
}
}
As you can see we update the map in the correct position and then we recalculate the matrix from that coordinate to the end.
This answer might look great since each query is still answered in O(1) constant time, however, if we analyze the time complexity of the update we can realize that the worst-case scenario would be if the update happens in coordinate {1, 1} because that would mean that the entire prefix2D Matrix is going to be recalculated.
The overall time complexity of this solution would be O(n^2 + (K * N^2)) since in the worst-case scenario all actions are updates that happen on the coordinate {1,1}.
This is going to give us a TLE verdict, and interestingly enough this solution has a time complexity equal to the iterative solution. 🙃😆
Before diving into the solution to this particular problem make absolutely sure you have read my Beginner's Segment Tree Introduction since this post assumes you totally understand how this technic works and how it's implemented.
Basically, a segment tree allows us to know the sum of all elements in a range, it can also be used to know the minimum or maximum value in a range, and allows us to make updates, both of these operations are done in a very efficient O(log(N)) way.
NOTE: in computer science, we work with log in base 2.

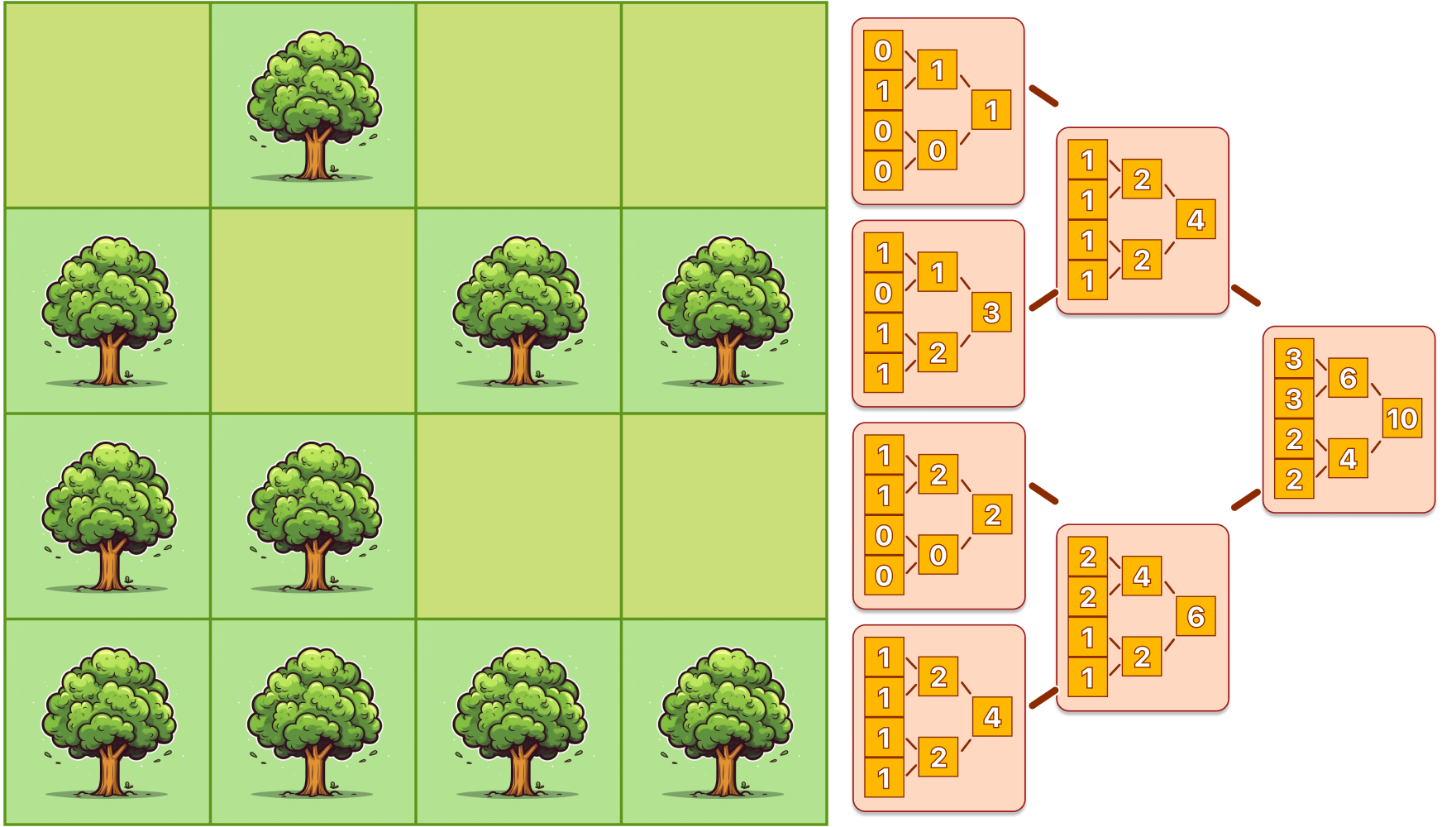
Above you can visualize the segment tree in action. on an array of the size shown it might not look very efficient, but when the array becomes very large it becomes clear how the segment tree makes our queries super efficient in log(N).

Above you can see the update in action, this operation is also very efficient having a time complexity of log(N).
Knowing this structure, we can solve the problem at hand by doing a segment tree for each row in a very similar way that we solved the first problem that didn't involve updates with a prefix sum array for each row.
I want to take this chance to show you a slightly different Implementation of the segment tree to the one that I showed in my Beginner's Segment Tree Introduction. The logic and theory remain completely the same, but now the implementation is nicely packed in a struct. This is necessary since we are working with several segment trees.
#include<iostream>
#include<vector>
#include<cmath>
typedef long long ll;
using namespace std;
struct segTree{
int n;
vector<ll>st;
segTree(int s){
n = 2 * pow(2, ceil(log2(s))) - 1;
st.resize(n, 0);
}
void update(int i, int newV){
i += n/2;
st[i] += newV;
while (i){
i = (i-1)/2;
st[i] = st[i*2+1] + st[i*2+2];
}
}
ll query(int ql, int qr, int l, int r, int i){
if(l >= qr || r <= ql)return 0;
if(l >= ql && r <= qr)return st[i];
int mid = (l+r)/2;
return query(ql, qr, l, mid, i*2+1) + query(ql, qr, mid, r, i*2+2);
}
ll query(int ql, int qr){
return query(ql, qr, 0, n/2+1, 0);
}
// void print(){for(auto e:st)cout << e << " "; cout << endl;}
};
int main(){
int n, k; cin >> n >> k;
vector<segTree> mapSTrees(n, segTree(n));
char map[n][n];
for(int i=0; i<n; i++){
for(int j=0; j<n; j++){
cin >> map[i][j];
mapSTrees[i].update(j, map[i][j] == '*'?1:0);
}
// rowST.print();
}
while (k--){
int action; cin >> action;
if(action == 1){
int x, y; cin >> x >> y;
x--, y--;
if(map[x][y] == '*'){
mapSTrees[x].update(y, -1);
map[x][y] = '.';
}else {
mapSTrees[x].update(y, 1);
map[x][y] = '*';
}
}else{
int x1, y1, x2, y2; cin >> x1 >> y1 >> x2 >> y2;
x1--,y1--,x2--,y2--;
ll res = 0;
for(int row=x1; row <= x2; row++){
res += mapSTrees[row].query(y1,y2+1);
}
cout << res << "\n";
}
}
return 0;
}
Notice how everything is the same as in my post except for two minor changes.
Getting the size of the segment tree is now done in a single line with the help of the following formula: 2 * pow(2, ceil(log2(n))) - 1;
There are two query methods, one of them is responsible for actually calculating the answer with recursion and 5 parameters, and the other is just the public interface that only takes two arguments. This is simply to make the usage of the function easy for the user.
The building of each segment tree (performed in the segTree constructor) has a time complexity of O(n), where n is the size of the input array (or the row/column length of the map, in this case). This operation happens n times (once per row), leading to an overall time complexity of O(n^2).
The 'update' operation, where an element of the array is modified and the segment tree is subsequently updated, has a time complexity of O(log n). This operation might be performed n times within the 'k' operations, hence the worst-case time complexity would be O(k log n).
The 'query' operation, where a subarray sum is calculated, also has a time complexity of O(log n). In the worst-case scenario, this operation might be performed for all rows of the map within the 'k' operations, leading to an overall worst-case time complexity of O(nk log n).
Combining all of these operations, the overall time complexity in the worst-case scenario is O(n^2 + nk log n), which is about 28,100,000,000 operations. This solution finally shows improvement but it's still not efficient enough to avoid the TLE verdict.
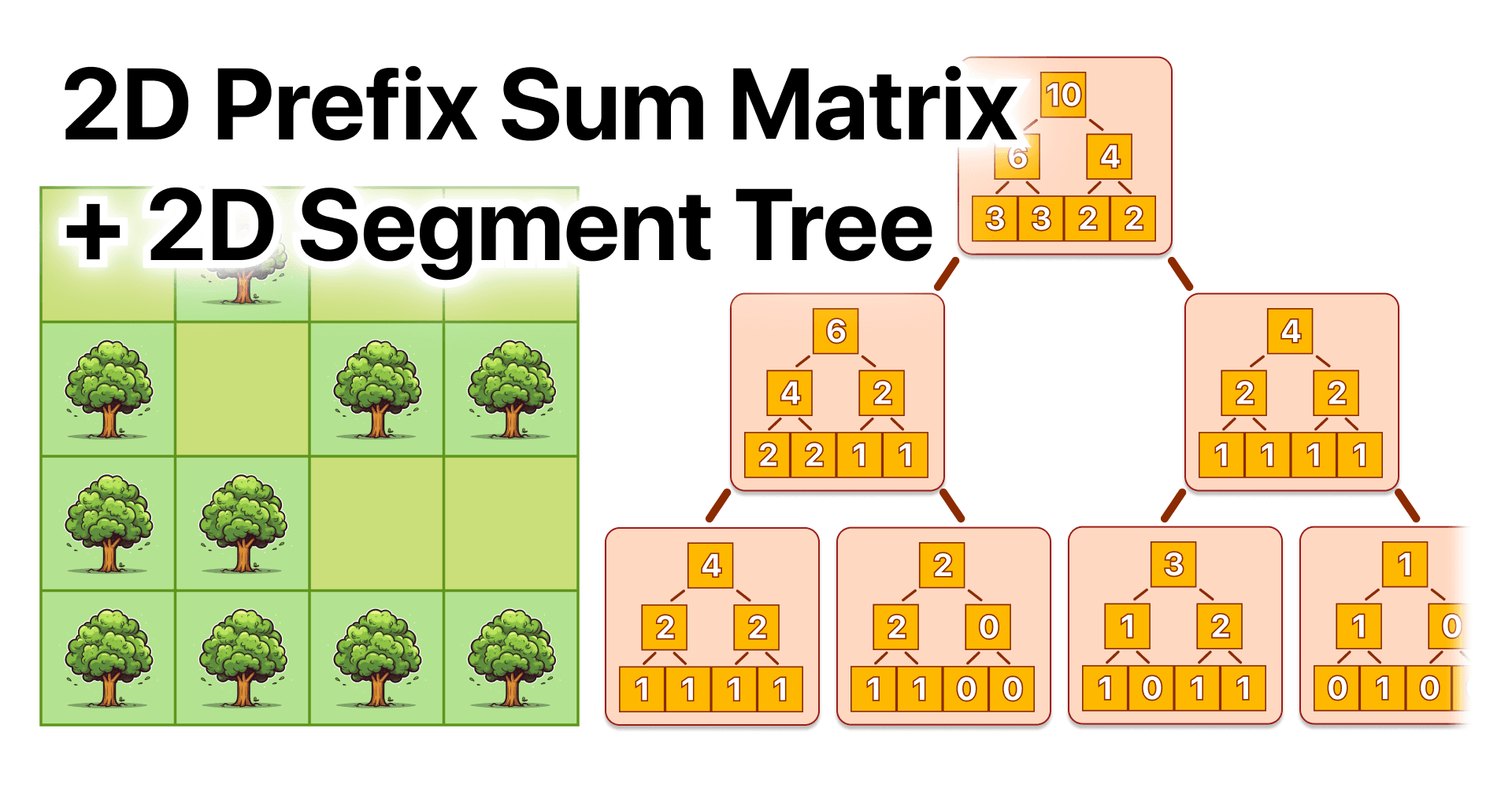
In a very similar way to the first problem in which we used a 2D prefix sum Matrix to avoid iterating over the rows, we need to apply that same optimization concept to this problem by using a 2D Segment Tree like this:
This is where having a nicely packed segment tree struct is extremely useful. In order to implement a 2D version we are going to create another additional structure that uses the 1D previously created version.
struct segTree2D{
int n;
vector<segTree> st;
segTree2D(int s){
n = 2 * pow(2, ceil(log2(s)))-1;
st.resize(n, segTree(s));
}
void update(int x, int y, int newV){
x += n/2;
st[x].update(y, newV);
while (x){
x = (x-1)/2;
st[x].update(y, newV);
}
}
ll query(int ql, int qr, int qt, int qb, int t, int b, int i){
if(t >= qb || b <= qt)return 0;
if(t >= qt && b <= qb)return st[i].query(ql, qr);
int mid = (t+b)/2;
return query(ql, qr, qt, qb, t, mid, i*2+1) + query(ql, qr, qt, qb, mid, b, i*2+2);
}
ll query(int ql, int qr, int qt, int qb){
return query(ql, qr, qt, qb, 0, n/2+1, 0);
}
};
Notice how this 2D segment Tree has all the same methods that the 1D version, we have the initialization:
vector<segTree> st;
segTree2D(int s){
n = 2 * pow(2, ceil(log2(s)))-1;
st.resize(n, segTree(s));
}
Notice how instead of the array of ints, we now have an array of segment trees, also, when we resize the vector we initialize the 1D segment trees at the same time st.resize(n, segTree(s));
The query works exactly the same but only over the rows, I like to manage the two pointers as top and bottom, and when the range is completely inside the range we access that particular segment tree and we perform the query for Left and Right.
Lastly, the update, in this case, is very simple because it's a sum segment tree, we just access the corresponding segment tree to the x row, we update the value in the y position on that array, and then we return until we reach the root at the same time that we update the value on the y axis of each segment tree along the way. However, keep in mind that min or max segment tree versions are much different.
For the update operation, the time complexity is O(log n). In the worst-case scenario, the update operation affects elements all the way up the segment tree, which has a height of log n.
For the query operation, the time complexity is O(log(n)^2). This is because the query operation may need to traverse the tree in two dimensions: once for the row and once for the column. In the worst-case scenario, this traversal happens over a height of log n in each dimension, resulting in a total time complexity of O(log(n)^2).
These complexities hold true assuming that the underlying 1D segment tree (segTree) operations (update and query) have time complexities of O(log n).
The overall Time complexity of this algorithm is O(N^2 + (q * (log(N)^2))) which results in approximately 100,000,000 + (200,000 * 196) = 139,200,000 operations which is well within our limit.
#include<iostream>
#include<vector>
#include<cmath>
typedef long long ll;
using namespace std;
struct segTree{
int n;
vector<ll>st;
segTree(int s){
n = 2 * pow(2, ceil(log2(s)))-1;
st.resize(n, 0);
}
void update(int i, int newV){
i += n/2;
st[i] += newV;
while (i){
i = (i-1)/2;
st[i] = st[i*2+1] + st[i*2+2];
}
}
ll query(int ql, int qr, int l, int r, int i){
if(l >= qr || r <= ql)return 0;
if(l >= ql && r <= qr)return st[i];
int mid = (l+r)/2;
return query(ql, qr, l, mid, i*2+1) + query(ql, qr, mid, r, i*2+2);
}
ll query(int ql, int qr){
return query(ql, qr, 0, n/2+1, 0);
}
};
struct segTree2D{
int n;
vector<segTree> st;
segTree2D(int s){
n = 2 * pow(2, ceil(log2(s)))-1;
st.resize(n, segTree(s));
}
void update(int x, int y, int newV){
x += n/2;
st[x].update(y, newV);
while (x){
x = (x-1)/2;
st[x].update(y, newV);
}
}
ll query(int ql, int qr, int qt, int qb, int t, int b, int i){
if(t >= qb || b <= qt)return 0;
if(t >= qt && b <= qb)return st[i].query(ql, qr);
int mid = (t+b)/2;
return query(ql, qr, qt, qb, t, mid, i*2+1) + query(ql, qr, qt, qb, mid, b, i*2+2);
}
ll query(int ql, int qr, int qt, int qb){
return query(ql, qr, qt, qb, 0, n/2+1, 0);
}
};
int main(){
cin.tie(nullptr);
ios_base::sync_with_stdio(false);
int n, k; cin >> n >> k;
segTree2D SegTreeMap(n);
char map[n][n];
for(int i=0; i<n; i++){
for(int j=0; j<n; j++){
cin >> map[i][j];
SegTreeMap.update(i, j, map[i][j] == '*'?1:0);
}
}
while (k--){
int action; cin >> action;
if(action == 1){
int x, y; cin >> x >> y;
x--, y--;
if(map[x][y] == '*'){
SegTreeMap.update(x, y, -1);
map[x][y] = '.';
}else {
SegTreeMap.update(x, y, 1);
map[x][y] = '*';
}
}else{
int x1, y1, x2, y2; cin >> x1 >> y1 >> x2 >> y2;
x1--,y1--,x2--,y2--;
cout << SegTreeMap.query(y1, y2+1, x1, x2+1) << "\n";
}
}
return 0;
}
Competitive programming is vast and filled with seemingly endless complexities. Yet, as we explored these two problems, we realized that even the most intricate challenges have a variety of viable solutions, each with its own efficiency and uniqueness.
Iterative methods, prefix sum arrays, 2D prefix sum matrices, segment trees, and even their 2D counterparts - all these approaches offer unique insights into problem-solving, and I hope this post made you better understand the capabilities of each technic.
Remember, there is no one-size-fits-all solution in programming. The 'best' solution depends heavily on the problem at hand, the constraints we're working within, and, not least, your own creativity and understanding. Continue to explore, to learn, and to challenge yourself - every problem you encounter is an opportunity to grow.
I invite you to delve deeper, to question, and to play with the various strategies we've discussed. They're merely tools in your programming arsenal, and their real power is realized in their application.
Thank you for joining me on this journey. Keep the spirit of learning alive, and I hope to see you in future posts.
Let me know your thoughts and suggestions in the comment section below and wish you happy coding.